
Kleurenversie van de grafiek op p. 245 van Het raadsel literatuur.
Vijftig tinten en Romantiek, analyse op hoofdcomponenten (1000 meest frequente woorden). Uit het Engels vertaalde romans staan weergegeven met een E_ voor de auteur en verkorte titel, en oorspronkelijk
Nederlandstalige romans zijn aangeduid met N_. De O_ voor de Vijftig tinten-trilogie staat voor Overig. Maat: PCA, correlatieversie.
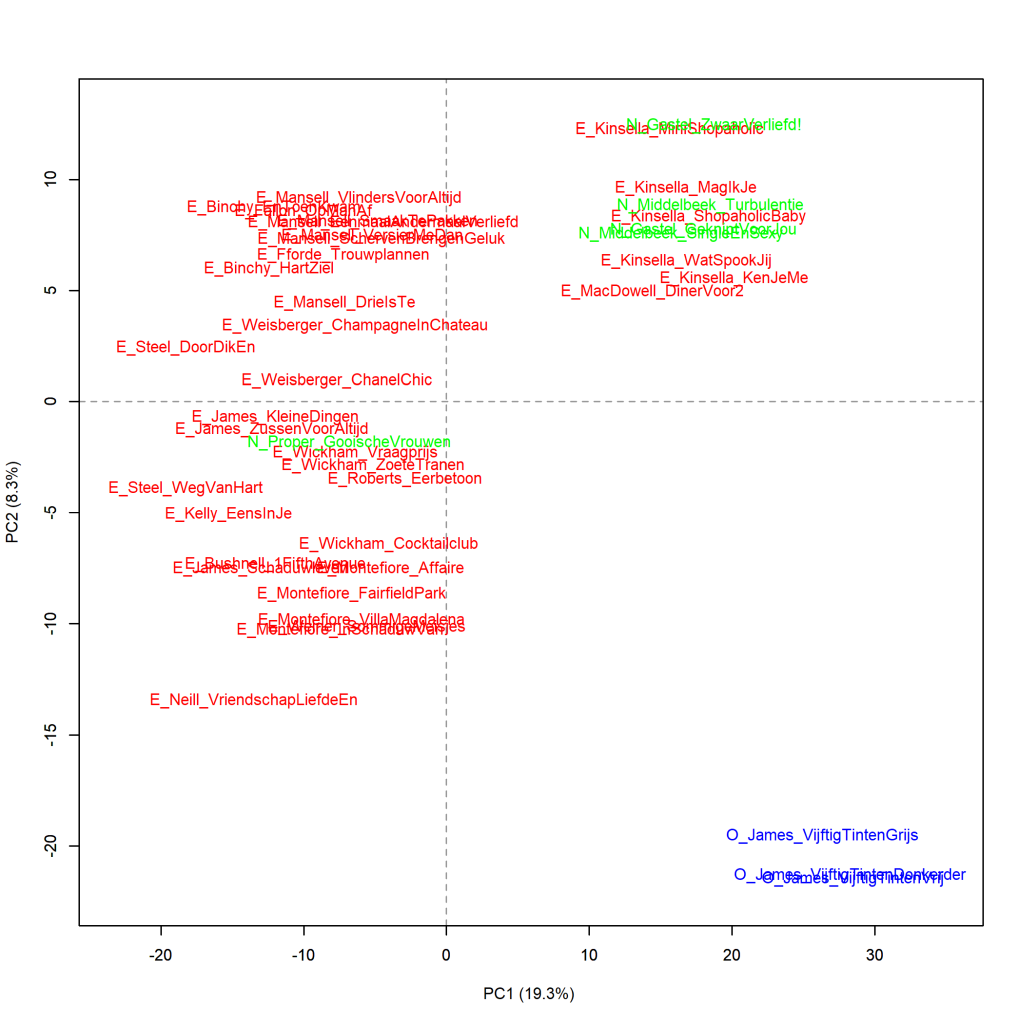
Ook deze grafieken zijn gemaakt met het Stylo Package for R. Zie Grafiek 4.5 voor meer informatie over het package en de verschillende maten.
Grafiek 9.2.1 Vijftig tinten en Romantiek
Clusteranalyse (1000 meest frequente woorden). Maat: Classic Delta.
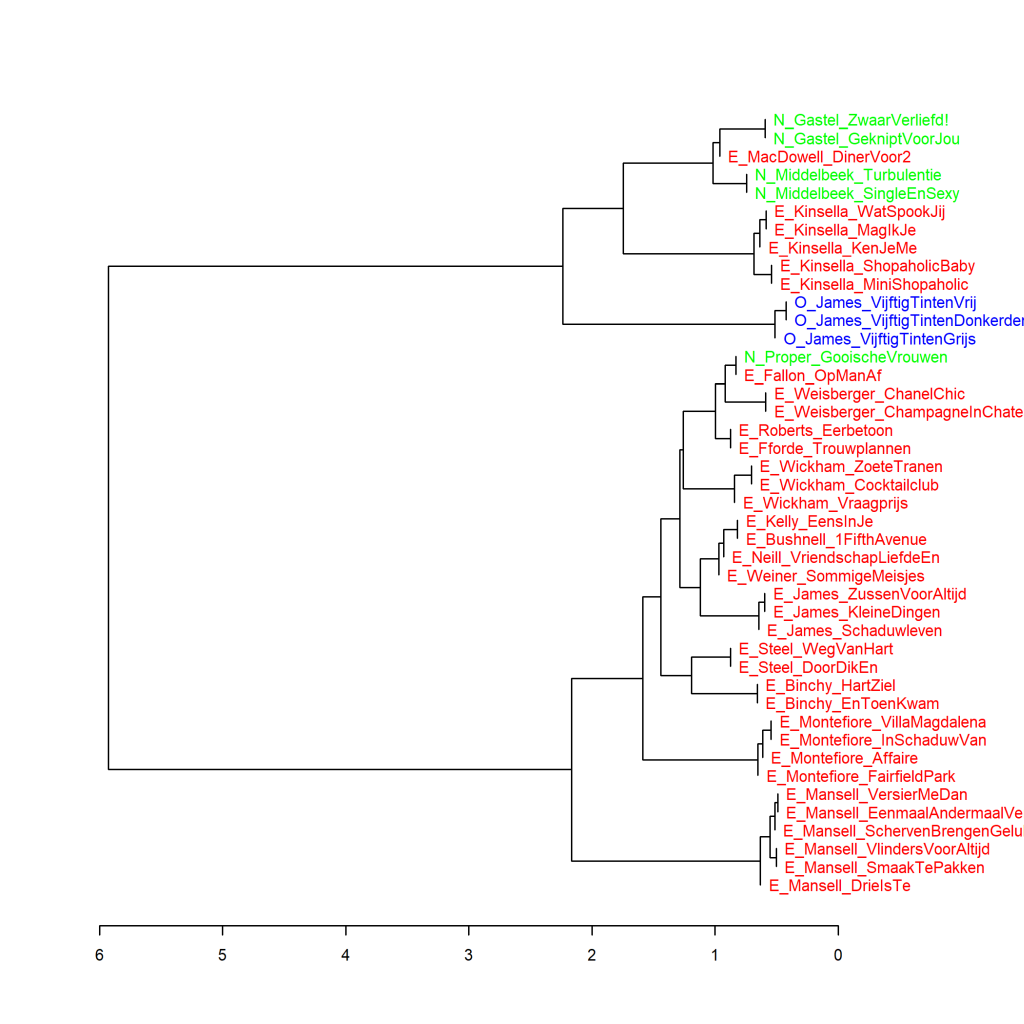
Ook in de visualisatie van deze clusteranalyse is duidelijk te zien dat boeken van dezelfde auteur gewoonlijk het meest op elkaar lijken. De afstand van de Vijftig tinten-trilogie tot de rest is in deze meting minder groot dan die lijkt in de analyse op hoofdcomponenten zoals gevisualiseerd in Grafiek 9.2: de trilogie staat iets meer dan twee Delta-scores af van de romans van Van Gastel, Macdowell, Middelbeek en Kinsella.Dat beeld verandert niet als we een hele serie clusteranalyses doen zoals gevisualiseerd in de bootstrap consensus tree in Grafiek 9.2.2.
Grafiek 9.2.2 Vijftig tinten en Romantiek
Bootstrap consensus tree (100 - 1000 meest frequente woorden, increment van 100, consensus strength 0.5). Maat: Classic Delta.
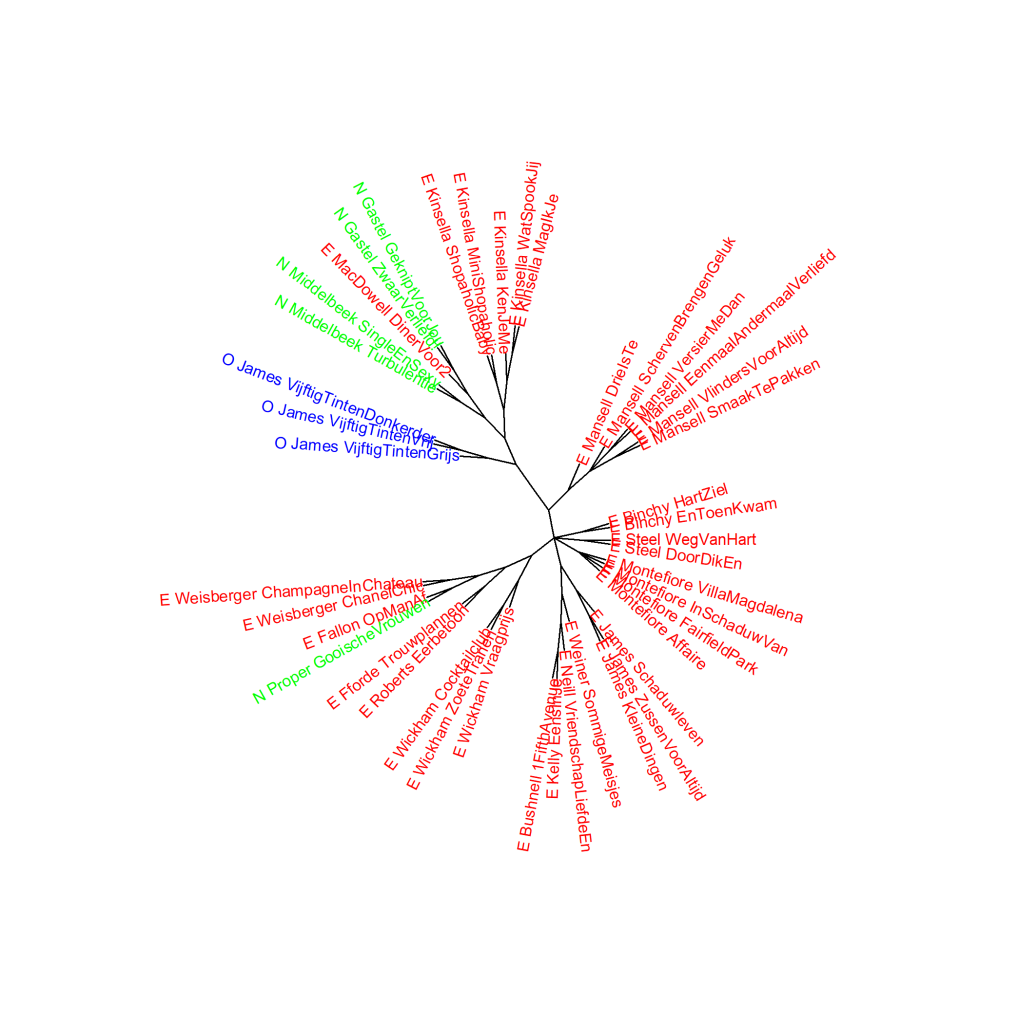
Conclusie
De extra metingen nuanceren het beeld dat de Vijftig tinten-trilogie wat woordfrequenties niet overlapt met de boeken uit de categorie Romantiek in het onderzoekscorpus: de afstand tot een subgroepje is vergelijkbaar met de afstand tussen de twee romans van Renate Dorrestein die in verschillende clusters voorkwamen in Grafiek 7.7. Meer in Het raadsel literatuur op p. 244-245.